词法分析器与正则表达式窥探
正则表达式介绍
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
正则表达式常见规则
构造正则表达式的方法:用多种元字符与运算符将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为”元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
普通字符
| 字符 | 描述 | 实例 |
|---|---|---|
[ABC] |
匹配ABC串内的所有字符 |
用[ogl]匹配google可以匹配googl |
[^ABC] |
匹配除了ABC串内的所有字符 |
用[^ogl]匹配google可以匹配e |
[A-Z] |
[A-Z] 表示一个区间,匹配该区间内的所有符号 |
[0-9]匹配0到9的数字 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r] |
用[ogl]匹配google可以匹配google不包括换行符 |
[\s\S] |
匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行 |
用其匹配google可以匹配google包括换行符 |
[\w] |
匹配数字,字母,下划线。等价于[A-Za-z0-9] | 例如可以匹配类似Ax0 |
非打印字符
| 字符 | 描述 |
|---|---|
\cx |
匹配由x指明的字符,如\cM匹配Control-M或回车符 |
\f |
匹配一个换页符 |
\n |
匹配一个换行符 |
\r |
匹配一个回车符 |
\s |
匹配任何空白字符,包括空格,制表符,换页符等等 |
\S |
匹配任何非空白字符 |
\t |
匹配一个制表符 |
\v |
匹配一个垂直制表符 |
特殊字符
| 字符 | 描述 |
|---|---|
$ |
匹配输入字符串的结尾位置 |
() |
标记一个子表达式的开始和结束位置 |
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
. |
匹配除换行符 \n 之外的任何单字符 |
[ |
标记一个中括号表达式的开始 |
? |
匹配前面的子表达式零次或一次 |
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符 |
^ |
匹配输入字符串的开始位置,当在方括号表达式中使用时,表示不接受方括号表达式中的字符集合 |
{ |
标记限定符表达式的始 |
| ` | ` |
限定符
| 字符 | 描述 |
|---|---|
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
? |
匹配前面的子表达式零次或一次 |
{n} |
n 是一个非负整数。匹配确定的 n 次 |
{n,} |
n 是一个非负整数。至少匹配n 次 |
{n,m} |
m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 |
从状态机的视角来审视正则表达式
以邮箱表达式的匹配规则对应生成的状态图为例
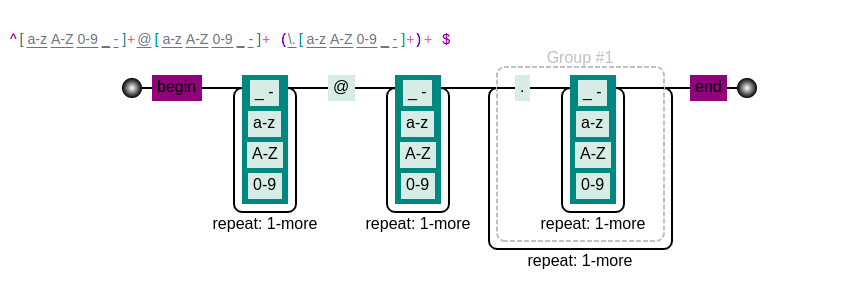
从状态图来看,首先我们会进入第一个匹配环节,可以匹配数字,字母和下划线一次或者多次,其实这里写代码的话就会对应着一个while循环。紧接着是@的匹配,然后类似第一个的循环。最后是两个循环的匹配,因为邮箱的格式可以有一个或者多个.xxx的形式。通过图形我们可以很直观的看到整个识别的过程。
另外其实也可以说明我们的每一个正则表达式都可以转化为一个状态图。
C语言对应的正则表达式函数结构概览
C语言也对正则表达式的识别进行了封装,使用时,我们只需要引入头文件<regex.h>即可。
主要包括以下几个函数
1 | int regcomp(regex_t *preg, const char *regex, int cflags); |
regcomp()函数
pmatch结构
1 | typedef struct { |